By Shweta Nayak, Data Scientist at AlgoAnalytics
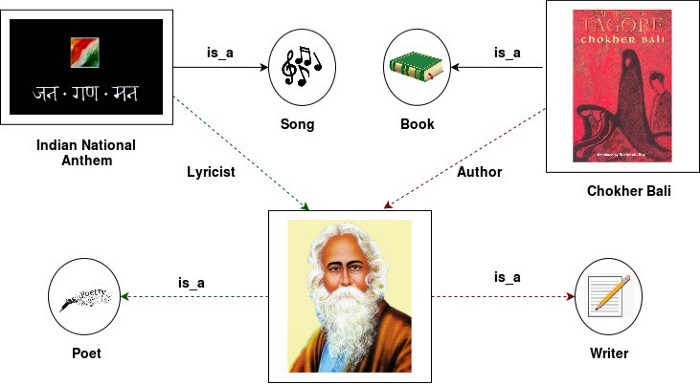
“Sir Rabindranath Tagore wrote Chokher Bali in 1903 and the Indian National anthem in 1911.”
This simple sentence has some useful information that is hidden. The implicit information is that Rabindranath Tagore was a poet and a writer. Pre-trained language models have exceptional capabilities to obtain state-of-the-art results on various NLP applications such as named entity recognition, question-answering, text classification, etc. However, if you ask language models such as BERT “Is Sir Rabindranath Tagore a poet or a writer?”, the answer might be a tangled tale. A pre-trained language model such as BERT performs poorly in language understanding and hence will not help to capture hidden relations such as “poet” or “author.”
To address this, researchers from Tsinghua University and Huawei Noah’s Ark Lab recently proposed a new model that incorporates Knowledge Graphs (KG) into training on large-scale corpora for language representation named “Enhanced Language RepresentatioN with Informative Entities (ERNIE)”[1]
How ERNIE achieves it:
Rich knowledge information in text can lead to better language understanding and accordingly benefits various knowledge-driven applications. To achieve this, ERNIE tackled two main challenges to incorporate external knowledge into language representation: Structured Knowledge Encoding, and Heterogeneous Information Fusion.
Structured Knowledge Encoding:
Structured Knowledge Encoding refers to how effectively we can extract and encode related informative facts in KGs for language representation models.[2]
In simpler words, given some text, we have to identify the entity mention and its context and label the entity mention with its respective semantic types. This task is called Entity Typing.
In the above sentence, without knowing that Chokher Bali and the Indian National anthem are a book and a song respectively, on the entity typing task, it is difficult to recognize the two identities of Sir Rabindranath Tagore, i.e. poet and writer.
Building Structured Knowledge Encoding involves the below steps:
- Named entities mentioned in the text will first be extracted and then aligned to the corresponding entities in KGs.
- To label Entities mentioned in the text, we can use tools such as TAGME[3].
Example: Sir Rabindranath Tagore wrote Chokher Bali in 1903 and the Indian National anthem in 1911.
In the above sentences Sir Rabindranath Tagore, Chokher, Bali Indian National anthem are labeled entities.
- The structure of the KGs(i. e. Entity) will be encoded with knowledge embedding algorithms such as TransE.
- Knowledge embedding for the labeled entities can be built using tools such as OpenKE[4]
- Entity embedding obtained in step 2 can be fed to the ERNIE model for training.
Heterogeneous Information Fusion:
Let’s consider the same example again; “ Sir Rabindranath Tagore wrote Chokher Bali in 1903 and the Indian National anthem in 1911.” It is difficult for language models to extract the fine-grained relations, such as the poet and author on the relation classification task as these two sentences are syntactically ambiguous for it (Language model may get confused with sentence structure “UNK wrote UNK and UNK” to “UNK wrote UNK in UNK”, where UNK stands for Unknown).
Heterogeneous Information Fusion refers to designing a special pre-training objective to fuse lexical, syntactic, and knowledge information.
For relation classification, ERNIE injects the knowledge information into language representation. To be specific, ERNIE modifies the input token sequence by adding two mark tokens to highlight entity mentions.
[HL] Sir Rabindranath Tagore [HL] wrote [TL] Chokher Bali [TL] in 1903 and the Indian National anthem in 1911.
These extra mark tokens play a role similar to position embedding in the conventional relation classification models. Then, we also take the[CLS] token embedding for classification. Tokens[HD] and [TL] for head entities and tail entities respectively.
Conclusion:
ERNIE outperforms traditional pre-trained language models for rich knowledge information extraction from text.
For detailed results on standard datasets such as FewRel, FIGER please refer to “ERNIE: Enhanced Language RepresentatioN with Informative Entities”[1]
ERNIE helps to build a knowledge graph system for financial, clinical, legal text data and to extract best-hidden knowledge out of it, as just some examples of potential applications. Further, we can build the graph database over it to extract the required information from text by just a single query.
We, at AlgoAnalytics, have built the application for Patient Knowledge Graph using ERNIE. For a detailed demo please click here.
Demo and Contact Info:
For demo visit our link https://algoanalytics.com/demoapp
For further information, please contact: info@algoanalytics.com
References:
[1] Zhang, Zhengyan, et al. “ERNIE: Enhanced Language Representation with Informative Entities.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, doi:10.18653/v1/p19-1139.
[2] Dai, Yuanfei, et al. “A Survey on Knowledge Graph Embedding: Approaches, Applications and Benchmarks.” Electronics, vol. 9, no. 5, 2020, p. 750., doi:10.3390/electronics9050750.
[3] “On-the-Fly Annotation of Short Text Fragments!” TAGME, tagme.d4science.org/tagme/.
[4] Thunlp. “Thunlp/OpenKE.” GitHub, github.com/thunlp/OpenKE.
[5] https://github.com/thunlp/ERNIE
