By Nikhil Pote, Associate Data Engineer at AlgoAnalytics
In today’s world data is generated at a rapid pace, especially in enterprises where a vast amount of data is stored digitally. Enterprises may store data in various formats such as text, image, speech etc. While making business decisions, or even regular business transactions, it is often necessary to search and recollect specific pieces on information from this vast ocean of data. It would be a great advantage if Enterprise Search Engines [1] could search through not only the text data but also through images and speech data quickly. In order to achieve this, big data technologies can be combined with machine learning capabilities and boost search efficiency. Such Enterprise Search Engine will save both time and efforts on data search.
At AlgoAnalytics, we have developed an AI powered search engine which can search multiple enterprise data sources (Cloud Drives, Disks, Network share) and formats (text, documents, images).
Architecture of the Search Engine:
There are 3 main steps involved in the Enterprise Search Engine’s working process, as illustrated in Figure 1.
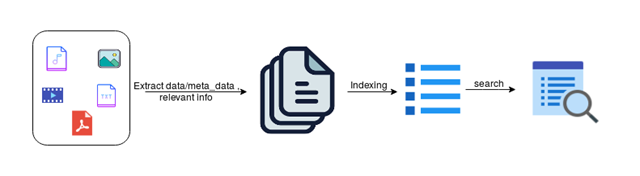
Figure 1 Steps in the Search Engine
1. Data Ingestion:
Data can be provided through any type of cloud storage (Amazon/GCP/Azure). Enterprise Search Engine can handle heterogeneous data sources that can scale up to Petabytes of Data. Spark clustering [2] is used to provide distributed and scalable processing which enables processing multiple files simultaneously with ease.
2. Data Preprocessing and Extraction:
Once data is stored on the cloud, spark dataframe is created which contains all file paths along with information related to the files. Data is classified whether its document, image or speech in the spark dataframe. From here on, the preprocessing and extraction process is done differently for all the classified types. In order to extract the data from document files, Apache Tika [3] content detection and analysis framework is used. It is a powerful tool for getting data from almost all types of text files. Python’s NLTK [4] library is used to preprocess the text data. Now TF-IDF (Term Frequency–Inverse Document Frequency) [5] feature extraction algorithm is used on the extracted text to get the important keywords present in the document.
Object detection is done in order to identify and locate all the objects present in image files. The Inception ResNet-v2 CNN model [6] which is trained on the ImageNet database is used for object detection. The CNN model is 164 layers deep and can classify images into 1000 object categories. As a result, the network has learned rich feature representations for a wide range of images. These detected objects are stored for further searching purposes.
3. Data Indexing:
Once data is extracted from the files, indexing is done with the help of Elasticsearch [7] which is a distributed engine based on the Lucene library. This indexed data will act as tags based on which searching of the files is done.
One of the important features of Enterprise Search Engine is automated index update. Whenever files are updated, deleted or new files are added onto then the files along with tags are updated and indexed into the Elasticsearch. This is achieved by using apache airflow workflow management platform pipeline. This pipeline is triggered in specific intervals (for example, daily) and will run data extraction and indexing parts of the system. As the process is automated, no manual interventions are required even if new files are added or existing files are modified.
Enterprise Search Engine is dockerized which enables faster deployment of the system and also enables application portability. Deployment of the search engine can be done on a private cloud or internal system.
Typical Applications:
Enterprise Search Engine which acts as an “insight engine” can be used for knowledge management as it processes billions of files. This is applicable for organizations collecting a vast amount of data such as publications, research companies, E-commerce companies, government offices, etc. This search engine can also be used to gain insightful information on large files. For example, recruitment agencies could use this for searching through a large database of resumes. This engine can help them shortlist candidates bases on job requirement just in a matter of seconds.
This Enterprise Search Engine solution developed at AlgoAnalytics with the power of big data and understanding of deep learning will help enterprises to improve productivity, business intelligence, enterprise search optimization and time management.
For demo visit our link https://algoanalytics.com/demoapp
For further information, please contact: info@algoanalytics.com
References:
[1] Enterprise Search Engine: https://en.wikipedia.org/wiki/Enterprise_search
[2] Apache Spark: https://spark.apache.org/
[3] Apache Tika: https://tika.apache.org/
[4] NLTK — Natural Language Toolkit: https://www.nltk.org/
[5] TF-IDF — Term Frequency–Inverse Document Frequency: https://en.wikipedia.org/wiki/Tf%E2%80%93idf
[6] Inception ResNet-v2 CNN Model: https://keras.io/api/applications/inceptionresnetv2/
[7] Elasticsearch: https://www.elastic.co/elasticsearch/
For further information, please contact: info@algoanalytics.com
