By Nirvisha Soni
The stock market is an important aspect of the economy and can be impacted by a variety of factors. One of these factors is the information available to investors and traders, particularly in the form of news articles. News articles about a company or the economy as a whole can provide valuable insight and help predict the performance of the stock market.
How do news articles play a key role in the stock market?
Information regarding a company’s present and future conditions, those of its rivals, and the situation of the economy as a whole can be found in news articles. For instance, the publication of an earnings report by a corporation affects the stock market significantly. The release of earnings reports can have a big impact on the stock market because they are a vital indicator of a company’s financial health and performance. The stock price of the company is likely to rise if the earnings report demonstrates solid financial performance, such as increasing revenue and profits. On the other hand, the stock price of the company may fall if the earnings report reveals poor results, such as decreasing revenue and profits.
Individuals usually sell stocks in response to negative news whereas buy stocks on receiving positive news. However it is to be noted that this is not always the case as positive news for some stocks can be a negative news for others and vice versa. Investors and traders can more accurately estimate the performance of the stock market and make decisions that are consistent with their investing objectives by staying up to date on the most recent news and happenings.
However, it’s crucial to remember that not all news reports are created equally and that some might not be credible or truthful. Before making any financial decisions based on news items, it is essential to assess the information’s source and take into account any possible biases.
How does Natural Language Processing help in news articles analysis for the stock market?
Artificial intelligence (AI) has a subfield called Natural Language Processing (NLP) that focuses on how computers and humans interact. The goal of NLP is to make it possible for computers to comprehend, analyze, and produce human language in a manner that closely resembles that of a person.
In the context of news articles and the stock market, NLP can help in several ways. For example, NLP can be used to extract pertinent data such as company names, financial indicators, and market movements from news articles. The performance of certain stocks or the stock market as a whole can then be predicted using this information. NLP can also be used to classify news articles as positive, negative, or neutral based on their sentiment. For instance, a positive article about a company’s strong earnings report can indicate an increase in stock value, while a negative article about a lawsuit can indicate a decrease in stock value. With the help of NLP, an article discussing a company’s successful product launch can be classified as enthusiastic and optimistic, while an article discussing a data breach can be classified as negative and concerned. This information can be used to make predictions about the stock market and specific stocks.
Summarization of news articles for stock market prediction
The stock market relies heavily on news articles to update investors and traders on the most recent developments in businesses, markets, and industries. However, it might take a lot of time and energy to go through the enormous amount of information that is available in the news. This is where summarization comes in, as it can help investors and traders quickly and efficiently process the most relevant information for stock market prediction.

The above demonstrated technique of condensing a lengthy document or collection of documents into a more manageable and brief version while retaining the key points is known as summarization. Summarization can assist investors and traders in swiftly identifying significant trends, events, and insights that may have an influence on their investments in the context of news stories and the stock market.
Models evaluated for the task of news articles summarization –
Hugging Face is an open-source library and platform for natural language processing (NLP) that was founded in 2016. It provides state-of-the-art pre-trained models for various NLP tasks, such as text classification, summarization, sentiment analysis, question answering, and language translation, among others. Following models offered by Hugging Face are used to compare their performance for news articles summarization —
1. Sshleifer/distilbart-cnn-12–6 is a pre-trained language model developed by Sasha Shleifer and hosted on Hugging Face’s model hub. It is a distilled version of the larger BART (Denoising Autoencoder-based Generative Pretrained Transformer) model and has 12 Transformer layers and a hidden dimension of 672.
2. Philschmid/flan-t5-base-samsum is a pre-trained language model developed by Phil Schmid and hosted on Hugging Face’s model hub. It is based on the T5 (Text-to-Text Transfer Transformer) architecture and has been fine-tuned on the SAMSum (Structured Argumentation Mining for Single-Document Summarization) dataset for single-document summarization tasks.
3. Google/Pegasus-Xsum model is a state-of-the-art language model developed by Google and fine-tuned by Hugging Face. It is designed to generate human-like text summaries from longer documents or articles and provides a highly advanced solution for text summarization, making it a valuable resource for businesses, researchers, and individuals looking to extract insights from large amounts of text data.
4. T5-Base_GNAD has been trained on the Google News Annotated Dataset (GNAD), which is a massive corpus of text data sourced from news articles and newswire services. This allows T5-Base_GNAD to have a strong understanding of current events, news, and general knowledge, making it a valuable tool for applications in information retrieval and question-answering.
5. T5-small is a pre-trained language model developed by Google’s AI research team, called Google Brain. T5 stands for “Text-to-Text Transfer Transformer,” and it is a transformer-based architecture that was pre-trained on a large corpus of text data. One of the unique features of T5 is its “text-to-text” approach, which means that it is trained on a diverse set of tasks that are all formulated as text-to-text transformations. Despite its smaller size, T5-small still achieves competitive performance on a wide range of natural language processing tasks.
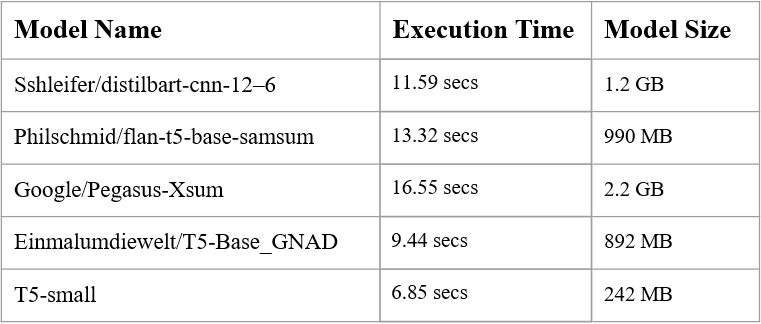
The models above were compared while maintaining similar hyper-parameters in order to create a fair comparison. All the models were compared on the basis of execution time, model size and the preciseness of summaries generated. Three best performing models were T-small, Einmalumdiewelt/T5-Base_GNAD and sshleifer/distilbart-cnn-12–6. T5-Base_GNAD is a T5 model, which is a powerful transformer-based model that has been trained on a diverse range of NLP tasks, including summarization. The T5-small model is the smallest variant of the T5 family of models, with only 60 million parameters, which makes it more lightweight and faster to deploy than larger models. On the other hand, SSHleifer/DistilBart-CNN-12–6 is a distilled version of the popular Bart model and is specifically designed for text summarization tasks. It has been fine-tuned on several summarization datasets and has shown to perform well on various summarization benchmarks. While T5 has the ability to perform summarization tasks, it is not as specialized as DistilBart and may require fine-tuning on a specific summarization dataset for optimal performance.
In conclusion, the choice between T-small, SSHleifer/DistilBart-CNN-12–6 and T5-Base_GNAD will largely depend on the specific requirements of the summarization task and the trade-off between speed and accuracy desired. All three models are highly capable, and choosing one over the other will depend on the specific context and requirements of the task.
References –
- HuggingFace community: https://huggingface.co/
- HuggingFace‘s sshleifer/distilbart-cnn-12–6: https://huggingface.co/models?filter=zero-shot-classification
