by Nooruddin Peerzada
We all have clicked great pictures except that one tiny detail, which, if removed, would make the picture just perfect or seen a picture of ourselves which is great but the background and other elements in it forbid you from posting it online. Now, not everyone is well-versed with Photoshop. Wouldn’t it be great if we could “cut out” any object, in any image, with a single click? Meta (formerly Facebook) has come up with Segment Anything Model (SAM): a new Computer Vision AI model that can do just that for you. SAM is a promptable segmentation system with zero-shot generalization to unfamiliar objects and images, without the need for additional training.
Foundation Models like SAM have become quite popular due to its zero-shot transfer learning capabilities for unseen tasks. This capability is often implemented with prompt engineering and large-scale data. With the rise of foundation models in NLP, Meta AI has released SAM that could be considered as a component of a larger project which also includes tasks and data engine.
SAM Foundations
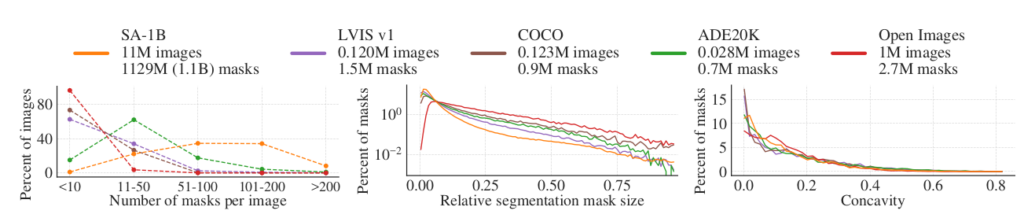
SAM has been dubbed as a foundation model for segmentation tasks. It has been trained on SA-1B dataset which consists of 11 million images having 1.1 billion masks and can be used for several downstream tasks. The dataset has been curated using a data engine which has three stages: (1) a model-assisted manual annotation stage, (2) a semi-automatic stage with a mix of automated predicted masks and model-assisted annotation, and (3) a fully automatic stage in which the model generates masks without annotator input. Mask quality has been estimated by computing the IoU between the masks of a randomly sampled image and the masks by professional annotators for the same image. Out of 500 randomly selected images (~50k masks), 94% of pairs have greater than 90% IoU. The SA-1B dataset has 11 times more images and 400 times more masks than the largest existing segmentation dataset Open Images. See Figure 1 Dataset Properties.
Like NLP foundational models, SAM makes use of promptable segmentation tasks. A prompt can be a set of foreground / background points, a rough box, mask and free-form text. The goal is to produce a valid mask even if the prompt is ambiguous. To resolve this ambiguity, the model is modified to give 3 mask outputs (subpart, part and whole object). Figure 2 Valid Masks shows three valid masks generated by SAM from a single ambiguous point prompt.

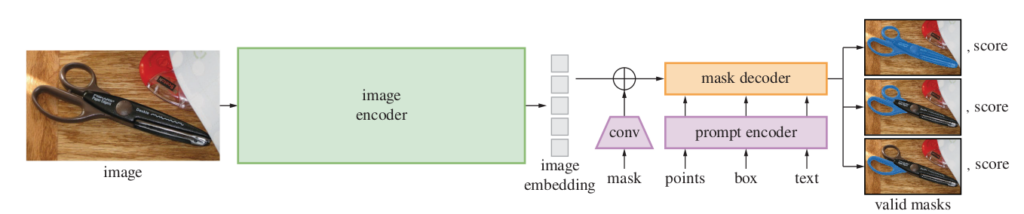
SAM has three components as seen in Figure 3 Model Architecture, an image encoder, a flexible prompt encoder and a fast mask decoder. For image encoding, a ViT-H transformer model is used to process high resolution images. The image encoder runs once per image and can be applied before prompting the model for a seamless experience. The image encoder has 632 million parameters. Point and box prompts are represented with positional encoding whereas text prompts use CLIP encodings. Dense prompts are embedded using convolutions and summed element-wise with the image embeddings. The decoder is a lightweight transformer that predicts segmentation masks using image and prompt embeddings. The prompt encoder and mask decoder have 4 million parameters. The image encoder takes ~0.15 seconds on an NVIDIA A100 GPU. Given a precomputed image embedding, the prompt encoder and mask decoder run in a web browser, on CPU, in ~50 ms. Linear combination of focal loss and dice loss have been used for training.
SAM has been experimented with a variety of zero-shot downstream tasks
- Zero-shot single point valid mask prediction
- Zero-shot edge detection has been achieved by prompting SAM with a 16 x 16 grid of foreground points. This results in 768 predicted masks. Redundant masks are removed by NMS and edge maps have been computed using Sobel filtering.
- Zero-shot object proposals have been generated by modifying the automatic mask generation pipeline and output the masks as proposals.
- Zero-shot instance segmentation has been implemented using an object detector and prompting SAM with its output boxes.
- Zero-shot text-to-mask (Experimental Phase)
SAM – Practical Applications
- AI assisted labeling: SAM supports automatic mask generations for the entire image. It also easily generates a mask using a point prompt for a specific object which can be refined further by annotators if required.
- Synthetic Data Generation: One challenge in industries like manufacturing is non-availability of datasets. SAM can be used in conjunction with the other models to generate synthetic datasets. You can paste the intended data from SAM to new backgrounds for making a diverse dataset. You could also use techniques like inpainting.
- Gaze based segmentation: SAM supports zero-shot single point valid mask evaluation technique which can be used to segment objects through devices like AR glasses based on where the subjects gaze. This gives the user a more realistic sense of the world as they interact with those objects.
SAM in Action – Generating Masks for an Entire Image
Meta AI has released the pre-trained models (~2.4 GB in size) and code under Apache 2.0 (a permissive license) following FAIR’s commitment to open research. It is freely accessible on GitHub. The training dataset is also available, alongside an interactive demo web UI.
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)


Conclusion
As compared to dedicated interactive segmentation models, SAM might not perform well. It can miss fine structures, hallucinate small, disconnected components and may not produce crisp boundaries. However, SAM is an attempt to make a generalizable model for variety of downstream tasks using prompt engineering. SAM is a component to be used in a much larger system. This is indeed a notable contribution making way for the development of foundational models in the field of computer vision.
References
- Paper: https://ai.facebook.com/research/publications/segment-anything/
- Demo: https://segment-anything.com/demo
- Dataset: https://segment-anything.com/dataset/index.html
- Blog: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
- Use Cases: https://blog.roboflow.com/sam-use-cases/
