By Aditi Kandarkar
In today’s information-driven world, staying updated with the latest news is essential, especially if you are a stock market enthusiast or a trader. The information from news articles can give major insights on a company which can further help a trader understand the stock conditions better. However, with the sheer volume of news articles being published every day, manually analyzing and categorizing them becomes an overwhelming task. This is where machine learning comes to the rescue. This blog explores the process of building a multilabel news classification model that takes in a news article and predicts its category with an accuracy of 77%.

What is Multilabel Classification?
It is a machine learning task where an instance can be assigned multiple labels simultaneously. In the context of news classification, an article can belong to multiple categories such as finance, business, banking, market share, commerce, etc. The goal is to develop a model that can assign relevant categories to a given news article accurately.
Training the model
To build an effective news classification model, a diverse and well-labeled dataset is crucial. The news data was fetched and downloaded from Google API. The obtained corpus was labelled manually and was used to train the model.
Furthermore, feature selection is done with Variance thresholding which is a technique used in machine learning to remove low-variance features or features with minimal changes across the dataset which may not contain much useful information for the learning algorithm from a dataset. The model is built on the training data using the feature vectors and their corresponding labels.
The two approaches used here are:
a) Binary Relevance:
An approach commonly used for multi-label classification problems, transforms a multi-label classification problem into multiple binary classification subproblems, where each subproblem is responsible for predicting the presence or absence of a single label. It involves assigning a binary value (usually 0 or 1) to indicate the relevance or non-relevance of an item with respect to a specific query or user preference, usually used in retrieval or recommendation systems.
b) Classifier Chains:
It is an extension of the binary relevance approach for multi-label classification, each label is treated as a sequence or chain, and the classifiers are trained in a specific order. The key idea is that each classifier in the chain takes into account the predictions of the previous classifiers in the chain as additional features. By considering the order of labels in the chain, the classifiers can exploit these dependencies to improve the overall prediction accuracy.
1. Bert:
BERT (Bidirectional Encoder Representations from Transformers) is a state-of-the-art language model developed by Google. It is based on the Transformer architecture and has revolutionized many natural language processing (NLP) tasks, including text classification, named entity recognition, question answering, and sentiment analysis.
2. Finbert:
FinBERT is a specialized variant of the BERT (Bidirectional Encoder Representations from Transformers) model that has been specifically trained for financial sentiment analysis. It is designed to analyze textual data in the financial domain and extract sentiment or sentiment-related information from financial news articles, earnings calls, social media posts, and other financial texts.
3. TF-IDF + Var Thresholding:
TF-IDF (Term Frequency-Inverse Document Frequency) is a feature representation technique that assigns weights to terms based on their frequency in a document and their rarity across a corpus. Var thresholding, on the other hand, refers to a method of feature selection that selects features based on their variance. Combining TF-IDF with variance thresholding can be an effective approach for feature selection in text classification tasks.
4. TF-IDF + Var Thresholding + Glove:
Combining TF-IDF, variance thresholding, and GloVe embeddings can be a powerful approach for text classification tasks, as it leverages both the frequency-based representation of TF-IDF, the feature selection capabilities of variance thresholding, and the semantic information captured by GloVe embeddings.
5. TF-IDF + Var Thresholding + Distillbert:
Combining TF-IDF, variance thresholding, and DistilBERT can be an effective approach for text classification tasks, as it combines the frequency-based representation of TF-IDF, the feature selection capabilities of variance thresholding, and the contextual understanding of DistilBERT.
The model consists of classes with a hierarchical structure which is composed of multiple sub-classes in total :

Evaluating the model and results
The next vital step includes Model evaluation, which helps to understand the model’s strengths, weaknesses, and its ability to generalize to new data. Some commonly used metrics are Accuracy score, precision, F1 score and hamming loss. Our model performs remarkably with a F1 score of 0.76 for binary relevance and for classifier chains as well.
Along with the TF-IDF + variance thresholding method, a few other models as well as their combinations were built and evaluated. Following are the performances of each technique:
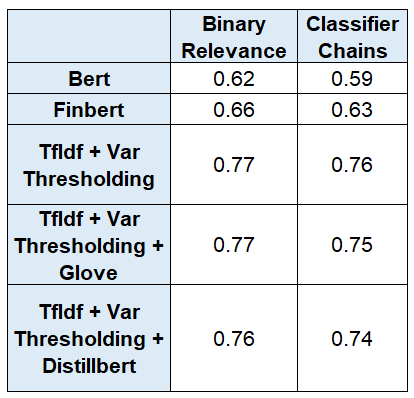
As one can observe, out of all the models TF-IDF + Var Thresholding with Binary relevance has the best performance and hence is considered.
After training and evaluating the model, it is vital to make predictions or estimate outcomes for new, unseen data points. Following is an example of prediction of the categories of the input news article

In this test case, the model takes in the news article and classifies it into multiple categories like finance, market news and updates, market updates and stock market updates.
Conclusion
Building a multilabel news classification model that takes a news article as an input and predicts the categories of news articles can greatly enhance the efficiency of news categorization. By leveraging machine learning techniques, the process is automated and enable users to quickly access relevant news based on their interests. With further refinements and optimization, such models can play a vital role in organizing and disseminating information effectively in the digital age.
