by Etisha Gurav
NLP is one the most rapidly evolving fields in Machine Learning and with the introduction of many paid and open source Large Language Model, it has become very easy to downstream various tasks in various domains involving text such as text generation, question answering and text classification. In this blog, we would be focusing on multilabel text classification. It is a machine learning technique that assigns predefined categories to texts and categorizes them in groups. To achieve this, pretrained models such as DistilBERT were fine-tuned on a custom dataset but with the advent of advanced models such as GPT-3, there is an opportunity to explore a new approach for fine-tuning multilabel classification models. This blog post aims to compare the traditional approach of fine-tuning using DistilBERT with the new approach of fine-tuning using GPT-3.
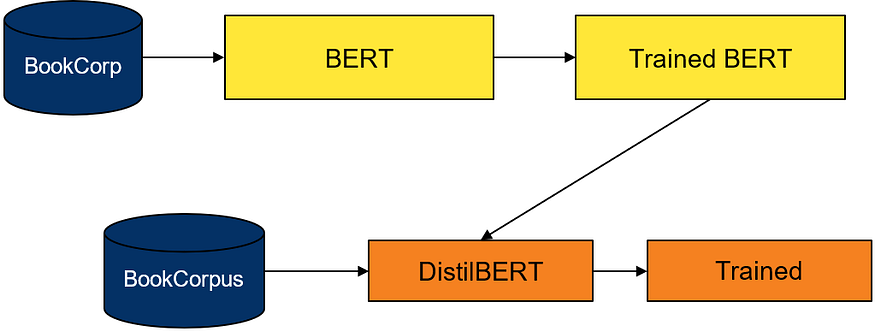
Overview of Traditional Approach: Fine-Tuning with DistilBERT
DistilBERT is smaller, cheaper and a faster version of BERT where the model is compressed by training on the same dataset as of BERT using the student-teacher learning approach (Knowledge Distillation). DistilBERT tries to mimic the output distribution of BERT by training with cross-entropy over the soft-targets. DistilBERT has the same architecture as BERT but with minor differences such as token type embeddings and pooler are removed and there is a 2x reduction in number of layers.
It was pretrained with three objectives:
- Distillation loss: the model was trained to return the same probabilities as the BERT base model.
- Masked language modeling (MLM): this is part of the original training loss of the BERT base model. When taking a sentence, the model randomly masks 15% of the words in the input, then runs the entire masked sentence through the model and has to predict the masked words.
- Cosine embedding loss: the model was also trained to generate hidden states as close as possible as the BERT base model.
This way, the model learns the same inner representation of the English language than its teacher model, while being faster for inference or downstream tasks.
To use DistilBERT for text classification, the model has to be finetuned on a custom dataset first. To achieve this, all the text has to be tokenized and each word be encoded into their input ids and attention masks(so that model knows which word is more important than the others). Once this is done, encoded inputs are then passed to the pretrained DistilBertSequenceClassification Model with a defined optimizer and loss function. Now this model is ready and can be used on the test data.
DistilBERT is an efficient model which can be used in resource-constrained environments and requires better results. It retains 97% of the performance with fewer parameters(66 M parameters in comparison to BERT’s 304M parameters).
Introduction to GPT-3: A New Paradigm
GPT-3 is an autoregressive, only decoder language model, which uses an attention mechanism, created by OpenAI. It is trained on 175 Billion parameters and 45TB of data, making it one of the largest models to be available. There are many models within the GPT-3 family catering to various types of use cases. Some of them are shown in the table given below.

All these models can be accessed by an API key provided by OpenAI.
Like DistilBERT, GPT-3 can also be down-streamed for various tasks. This is done by giving an example of the input in the form of a simple prompt and output in the form of completion of the prompt. For a classification task, the prompt could be the data to be classified and the output, the class that is assigned. An example is given below:

Since GPT-3 models take text as input, there is no need for an extra step of tokenizing the text as well as the output(in this case, class) which makes it very flexible for any kind of textual data. This greatly reduces the data preparation steps required for training a model. Once this step is done, the data can be passed through the desired GPT-3 model. Another benefit of this model is that it can handle very large text sequences due to its large context window, which is helpful in classification where the entire textual data would be required to understand which class is to be assigned. This greatly enhances the performances of the model.
Comparative Analysis: DistilBERT vs. GPT-3
For the comparative study of the performance of these two models, we have considered 13 labels with 100 texts under each label for fine tuning of the models.
For DistilBert, We had used the pretrained model ‘distilbert-base-uncased’ available from HuggingFace and created a Tokenizer as well as for Sequence Classification. However for GPT-3, the training data was created with prompt -> completion format and stored in jsonl file which could be passed into the GPT-3 models using the OpenAI API.
To evaluate the performances of these models, we have used the classification metrics such as precision, recall and accuracy. Precision would tell us how the model predicted the outcome correctly with respect to all its predictions whereas Recall would tell us how the model predicted the outcome with respect to all positive data points present in the training dataset. These metrics would tell us about the accuracy of the model.
Other parameters to consider for the comparison are the number of epochs and learning rate(in case of GPT-3, a learning rate multiplier is used). The following are the classification metrics results for DistilBert and GPT-3
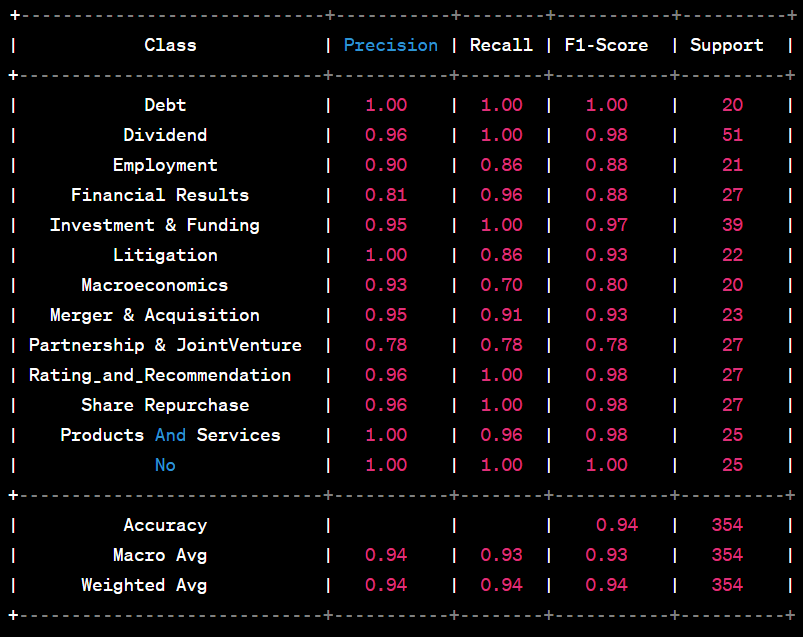

As seen above, Both the models, GPT-3 and DistilBERT, have a good accuracy scores of 94% and 95%, with the latter performing a little better. However, due to the advantage of minimal data preparation, GPT-3 would be preferred over DistilBERT.
Real-World Use Cases and Applications
Even after having similar accuracy scores on the same tasks, GPT-3 models and DistilBERT could be used for different cases and applications. Below are some of the real-world uses cases for each of the model:
DistilBERT
1. Sentiment analysis: DistilBERT models can be used to classify text as positive, negative, or neutral. This can be used to understand the sentiment of social media posts, customer reviews, and other text data.
2. Topic classification: DistilBERT models can be used to classify text into different topics. This can be used to organize documents, filter news articles, and recommend content to users.
3. Entity recognition: DistilBERT models can be used to identify entities in text, such as people, organizations, and locations. This can be used to extract information from documents, improve search results, and power chatbots.
GPT-3
1. Customer support: GPT-3 models can be used to classify customer support tickets by topic, sentiment, and other factors. This can help customer support agents to quickly and accurately identify the issue and provide the best possible resolution.
2. Product recommendation: GPT-3 models can be used to recommend products to users based on their past purchase history, interests, and other factors. This can help users to discover new products that they are likely to be interested in.
3. Fraud detection: GPT-3 models can be used to classify transactions as fraudulent or legitimate. This can help businesses to protect themselves from financial losses.
Conclusion
GPT-3 models and DistilBERT tend to have similar performances with respect to multilabel classification, however it is also important to consider factors such as the resources available for fine-tuning and cost. DistilBERT, due to its smaller size, can be used when there is resource constraint. Moreover DistilBERT works well when the classification is done over a dataset pertaining to a single domain and can also be easily fine tuned. It is also an open-source model which is available commercially, which when compared to GPT-3 models, which is not open-source, compares significantly higher. However, GPT-3 models show their strength when the dataset is not pertaining to a single domain and the outcome depends on varied sentiment and longer token length. Fine-tuning of models has become easier with the introduction of models like GPT-3, causing other open-source models to be at par with the recently introduced models which in turn will bring a lot of enhancements in the field of Natural Language Processing.
References
https://www.analyticsvidhya.com/blog/2022/11/introduction-to-distilbert-in-student-model/
https://www.kaggle.com/code/pritishmishra/text-classification-with-distilbert-92-accuracy
https://www.springboard.com/blog/data-science/machine-learning-gpt-3-open-ai/
https://en.wikipedia.org/wiki/GPT-3
https://swatimeena989.medium.com/distilbert-text-classification-using-keras-c1201d3a3d9d
