By km Alankrata
Introduction
RAG, or Retrieval-Augmented Generation, is a pivotal advancement in natural language processing that seamlessly merges retrieval-based and generation-based techniques. By first retrieving relevant information from a vast corpus of text and then using it to inform the generation process, RAG models produce contextually rich and accurate responses, particularly adept at handling long contexts and ensuring factual correctness and coherence.
This innovative approach not only enhances the relevance and quality of generated text but also offers adaptability across diverse domains, making RAG indispensable in open-domain conversational AI systems and other NLP applications where precision, context, and adaptability are paramount.
What is RAG?
Retrieval Augmented Generation (RAG) is an advanced artificial intelligence (AI) technique that combines information retrieval with text generation, allowing AI models to retrieve relevant information from a knowledge source and incorporate it into generated text. Retrieval Augmented Generation is a technique that enhances traditional language model responses by incorporating real-time, external data retrieval.
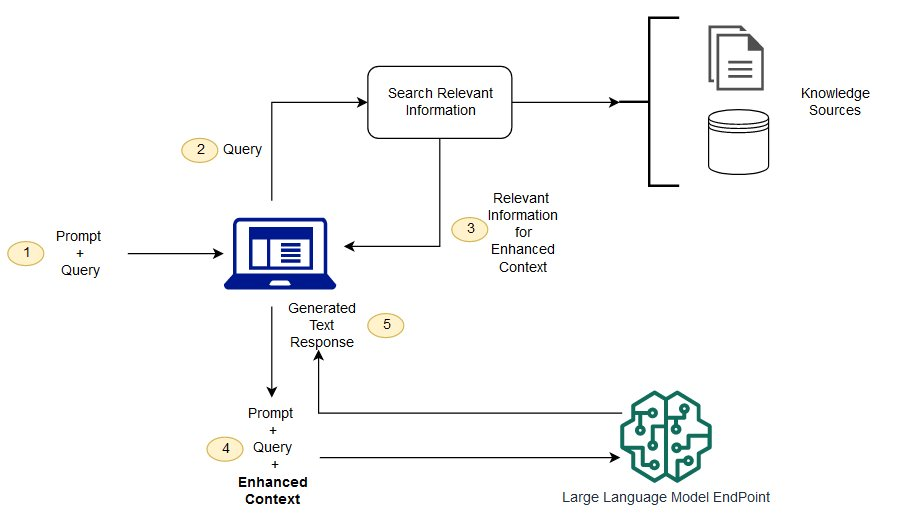
It starts with the user’s input, which is then used to fetch relevant information from various external sources. This process enriches the context and content of the language model’s response. By combining the user’s query with up-to-date external information, RAG creates responses that are not only relevant and specific but also reflect the latest available data.
This approach significantly improves the quality and accuracy of responses in various applications, from chatbots to information retrieval systems.
Use cases for Retrieval-Augmented Generation Systems
The use cases for RAG are varied and growing rapidly. These are just a few examples of how and where RAG is being used.
E-Commerce
In e-commerce, Retrieval-Augmented Generation (RAG) is a transformative technology that enhances customer experiences and operational efficiency.

By leveraging vast datasets and customer information, RAG can provide personalized product recommendations, streamline customer support with instant and accurate responses, and facilitate content creation and marketing efforts.
Moreover, RAG enables the creation of interactive product descriptions and facilitates real-time inventory updates, thereby optimizing the shopping experience for customers and driving business growth for e-commerce platforms.
Healthcare
In healthcare, Retrieval-Augmented Generation (RAG) uses advanced models to access medical knowledge and patient data, providing clinicians with personalized treatment recommendations, diagnostic support, and research insights.
It enhances communication between healthcare providers and patients, accelerates medical discovery, and improves overall patient care.

Key Components of RAG
Tokens and Embeddings
Tokens are the individual units of text, like words or punctuation marks, that make up a piece of language. They’re like the building blocks of sentences.
Embeddings are numerical representations of these tokens, created by algorithms that analyze their context and meaning. It’s like translating words into numbers so a computer can understand them better. These numerical representations help computers understand the relationships between different words and use them in tasks like language understanding and generation.
There are many ways to convert text into vector embeddings. Usually this is done using a tool called an embedding model, which can be an LLM or a standalone encoder model.
Retrieval Models
Retrieval models in the context of architectures like Retrieval-Augmented Generation (RAG) play a vital role in accessing external knowledge for text generation. Similar to specialized librarians, these models sift through extensive data repositories to find relevant information essential for generating context-rich language outputs. They employ algorithms like vector embeddings, vector search, BM25, or TF-IDF to efficiently rank and select pertinent pieces of data.
By integrating this external knowledge, retrieval models enhance traditional language models’ capabilities, resulting in more informed and relevant text generation.
Generative Models
Generative models, within frameworks like Retrieval-Augmented Generation (RAG), play a crucial role in transforming retrieved information into coherent and contextually relevant text. Functioning akin to creative writers, these models leverage the selected data from retrieval models and synthesize it into grammatically correct and semantically meaningful text.
Typically built upon Large Language Models (LLMs), generative models infuse the raw data with a narrative structure, making it easily understandable and actionable. As the final piece of the puzzle in the RAG framework, generative models produce the textual outputs that users interact with, effectively bridging the gap between retrieved knowledge and user-friendly language outputs.
Frameworks used to build RAG Pipelines
Langchain
LangChain is a versatile framework for Python and TypeScript/JavaScript, simplifying the development of applications using language models. It enables chaining together of agents and tasks, facilitating interactions with models and data sources.
However, synchronization of libraries can be challenging, especially in projects with diverse Python libraries.
LlamaIndex
LlamaIndex is a newer framework catering specifically to LLM data applications with an enterprise focus.
Both LangChain and LlamaIndex offer extensive libraries for ingesting, parsing, and extracting data from diverse sources, enhancing utility for developers and data scientists.
What’s Next..?
In Part-II of this blog we’ll be exploring how we can implement a basic Retrieval-Augmented Generation pipeline using the LangChain framework and pass our own Insurance Policy Clauses document as a knowledge base for the LLM to generate responses.
References
[1] https://aws.amazon.com/what-is/retrieval-augmented-generation/
[2] https://cloud.google.com/use-cases/retrieval-augmented-generation
[3] https://research.ibm.com/blog/retrieval-augmented-generation-RAG
