By Chithambarash S E
Introduction
Large language models (LLMs) have made significant strides in natural language processing, demonstrating impressive capabilities in text generation, translation, and question-answering tasks. However, their training on vast amounts of data can inadvertently introduce biases and harmful content. Whether due to privacy concerns, outdated information, or biases, the ability to unlearn certain pieces of information from these models is becoming essential.
In this blog, we explore LLM unlearning, its techniques, and its real-world implications. Drawing insights from recent research, we’ll discuss how unlearning works in LLMs and the future of this transformative capability.
What is LLM Unlearning?
LLM unlearning is the process of selectively removing specific information or patterns from an LLM’s memory without retraining the model from scratch. This is crucial for ensuring these models align with ethical standards and avoid generating harmful or biased content. It also helps protect sensitive data and intellectual property. Unlearning may be necessary for a variety of reasons:
Privacy violations: If a model inadvertently memorizes personal data.
Biases: To mitigate learned biases related to gender, race, or other sensitive areas.
Outdated information: When a model contains outdated or incorrect facts that need to be purged/updated.
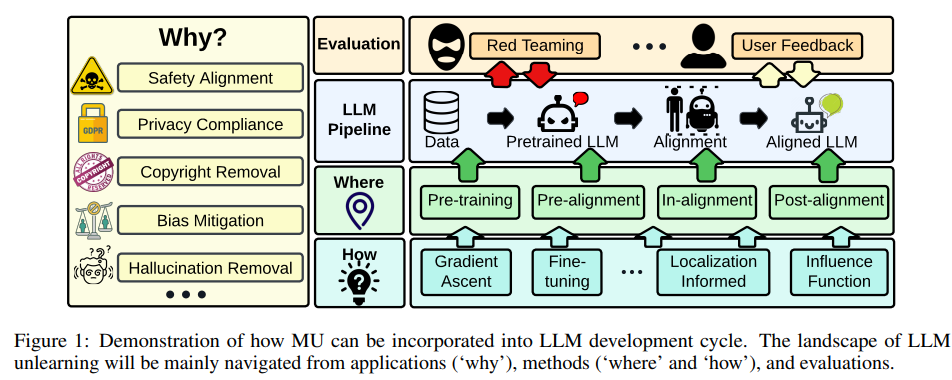
Challenges of Forgetting in Large Language Models (LLMs)
The challenge lies in efficiently removing the targeted information while retaining the integrity of the rest of the model’s knowledge.
Unlearning is trivially satisfied if we can just retrain the model without the undesired data. However, we want something better because (1) retraining can be expensive, and (2) it can be a lot of work just to find out what to remove from training data. This leads us to ask the key question: How do we selectively forget?
Methods for LLM Unlearning
Many different approaches have been explored across various research studies. Let’s understand some of the most commonly applied techniques for unlearning:
Note: Each method for unlearning has its own pros and cons, and understanding their mechanics helps us appreciate the complexity of this task.
1. Gradient Ascent (GA)
How it works: Gradient ascent is one of the most basic yet powerful methods for unlearning. In the context of unlearning, GA works by adjusting the model’s weights to minimize the likelihood of producing undesirable outputs. Specifically, it maximizes the loss or mis-prediction on data that we want the model to forget (the “forget set”). The idea is that by updating the model in the opposite direction of the desired gradient (which typically helps the model learn), you essentially “unlearn” that specific data or behavior.
For example, suppose a language model frequently outputs harmful or undesirable responses to certain prompts, like predicting the word “violence” after the prompt, “How can I harm someone?”. To unlearn this harmful association, GA would adjust the model’s weights by updating the gradient in the opposite direction of the learned association. As a result, the probability of predicting harmful words like “violence” or “gun” in response to this prompt is reduced.
Advantages:
- Gradient ascent is a computationally efficient method, especially for small unlearning datasets.
- It avoids the need to retrain the entire model.
- It works well when the goal is to stop generating specific undesirable outputs, even when examples of correct outputs are not available.
In the NeurIPS 2023 Machine Unlearning Challenge, a baseline method using simple gradient ascent on the “forget set” achieved moderate success (~0.06 in empirical accuracy), showing that even a straightforward method like GA can effectively contribute to unlearning in large models(llm_text).
Challenges: GA can be sensitive to hyperparameters, such as the learning rate, which can lead to catastrophic model failure if not tuned correctly. Catastrophic forgetting is a risk where the model unlearns more than intended.
2. Negative Preference Optimization (NPO)
How it works: Negative preference optimization (NPO) is a more refined version of gradient ascent, designed to address some of its shortcomings, such as catastrophic collapse. NPO treats the “forget data” as exclusively negative examples, focusing on reducing the model’s prediction accuracy on this set. By reframing unlearning as a minimization problem (reducing the likelihood of forgotten data) instead of maximizing the error, NPO avoids excessive forgetting of unrelated data.
For example, suppose a model has learned harmful biases from specific examples (e.g., gender or racial biases in job recommendation algorithms). Using influence functions, we could identify the exact data points contributing most to these biases. By removing the influence of these points, the model can be “unlearned” from making biased predictions.
However, calculating influence functions, especially in large-scale models, can be computationally expensive. Also, since this method relies on approximations, it may reduce unlearning effectiveness, particularly in larger models.Influence functions have traditionally been used in classical machine learning but are increasingly being applied to large language models for tasks like bias removal and responsible AI development.
Advantages:
- NPO mitigates the risk of catastrophic collapse and focuses solely on the negative examples,
- It ensures that unlearning is confined to the data that needs to be forgotten without affecting the model’s generalization ability.
- Though NPO requires careful tuning and loss-function design, it offers more precision in unlearning tasks.
It’s important to highlight that there are several variations of GA and techniques that can enhance its efficiency, such as the Relabeling Approach and Parameter-Efficient Fine-Tuning (PEFT). When applied effectively, these methods can provide substantial performance improvements.
3. Influence Function-Based Methods:
While not commonly used in LLM unlearning due to computational complexity, influence functions have shown promise in recent research. Influence functions measure how specific data points affect a model’s predictions by estimating the impact of removing those points. In the context of LLMs, they can be used to understand which training examples impact specific model behaviors the most.
This method is rooted in classical statistics but can be adapted for unlearning by identifying which data points contribute most to a given prediction. While influence functions typically involve calculating the second-order derivatives of the loss function (i.e., inverting the Hessian matrix), newer methods optimize this process to make it more computationally feasible.
Some recent advancements include:
1) Integration with Second-Order Optimization:
Jia et al. (2024) showed that influence functions can be integrated with second-order optimization. This transforms static, one-shot influence unlearning into a dynamic, iterative second-order optimization-driven unlearning method.
In their approach, they iteratively compute the influence of training examples on the model’s behavior for specific unlearning targets. Using this information to guide the optimization process, they achieved more effective unlearning than traditional gradient-based methods.
2) Localized Weight Focus:
To mitigate approximation errors in influence function derivation, some approaches focus on localized weights that are salient to unlearning. This could involve first using gradient-based saliency to identify key weights, then applying influence function analysis only to these weights. This reduces computational complexity while maintaining the benefits of influence-based unlearning.
4. Just ask for unlearning.
Powerful instruction-following models like GPT-4 can cleverly simulate unlearning by responding to carefully crafted prompts. This approach is particularly interesting because it bypasses the need for gradient-based methods, offering a significant advantage from a system efficiency standpoint. The results can be comparable to those achieved by empirical unlearning techniques.
For instance, we could prompt the model to act as if it doesn’t recognize Harry Potter. This technique works well for widely known entities, facts, or behaviors that are deeply embedded in the model’s training data. The model essentially needs to “know” something thoroughly to convincingly “forget” it. However, the challenge becomes more complex for more obscure information, like the address of an unknown individual. Since the training data includes vast amounts of information, we risk amplifying the problem (akin to the Streisand effect) by precisely instructing the model to forget something, potentially reinforcing its presence in future responses.
It might be useful to note that humans don’t really “unlearn” a piece of knowledge, either.
When we claim to have forgotten something, it’s often because we initially learned it well enough to recognize it and then made a conscious choice that it’s no longer useful in our current world. Why should unlearning be any different for LLMs?
Conclusion
Unlearning is certainly a hard problem, given the time and computational costs, and whether it’s the right approach for our current problems is yet to be seen. Two key questions help guide this: (1) How fast and efficient is unlearning compared to retraining? and (2) How effectively is the “forget data” unlearned, and how does this impact the retained data?
Answering these questions might not be straightforward, given the black-box nature of deep learning. Large language models like GPT-4 or LLaMA consist of billions of parameters, and unlearning a single concept requires a deep understanding of where it is embedded. Nevertheless, the benchmarking crisis is getting better. For instance, TOFU, a benchmark focusing on unlearning individual authors by fine-tuning models, while WMDP focuses on unlearning dangerous knowledge, specifically on biosecurity, cybersecurity, and chemical security, and it provides 4000+ multiple-choice questions to test a model’s hazardous knowledge before/after applying unlearning.
LLM unlearning is key to ensuring that AI systems can adapt to changing ethical, legal, and informational needs. Whether through fine-tuning, neural editing, or retraining, the ability to forget may be just as important as learning for future AI. Ongoing research to make this process more efficient and scalable is crucial for responsible AI development.
References:
- Machine Unlearning in 2024 – Ken Ziyu Liu – Stanford Computer Science. http://ai.stanford.edu/~kzliu/blog/unlearning
- Large Language Model Unlearning – https://arxiv.org/abs/2310.10683
- Rethinking Machine Unlearning for Large Language Models – https://arxiv.org/abs/2402.08787
