By Sayali Pophale
Introduction
In today’s world, we’re overwhelmed with text from news articles, social media updates, and company reports, making it challenging to navigate through the vast amount of information. This becomes even tougher when we’re looking at specific documents. It’s crucial for investors, analysts, and companies to understand what’s being said about them. This blog looks at a new way to do this, using Topic Modelling Algorithms and Large Language Models (LLMs). By combining these tools, we make it easier to find the main ideas in a bunch of documents and explain them clearly.
The Role of Topic Modeling Algorithms
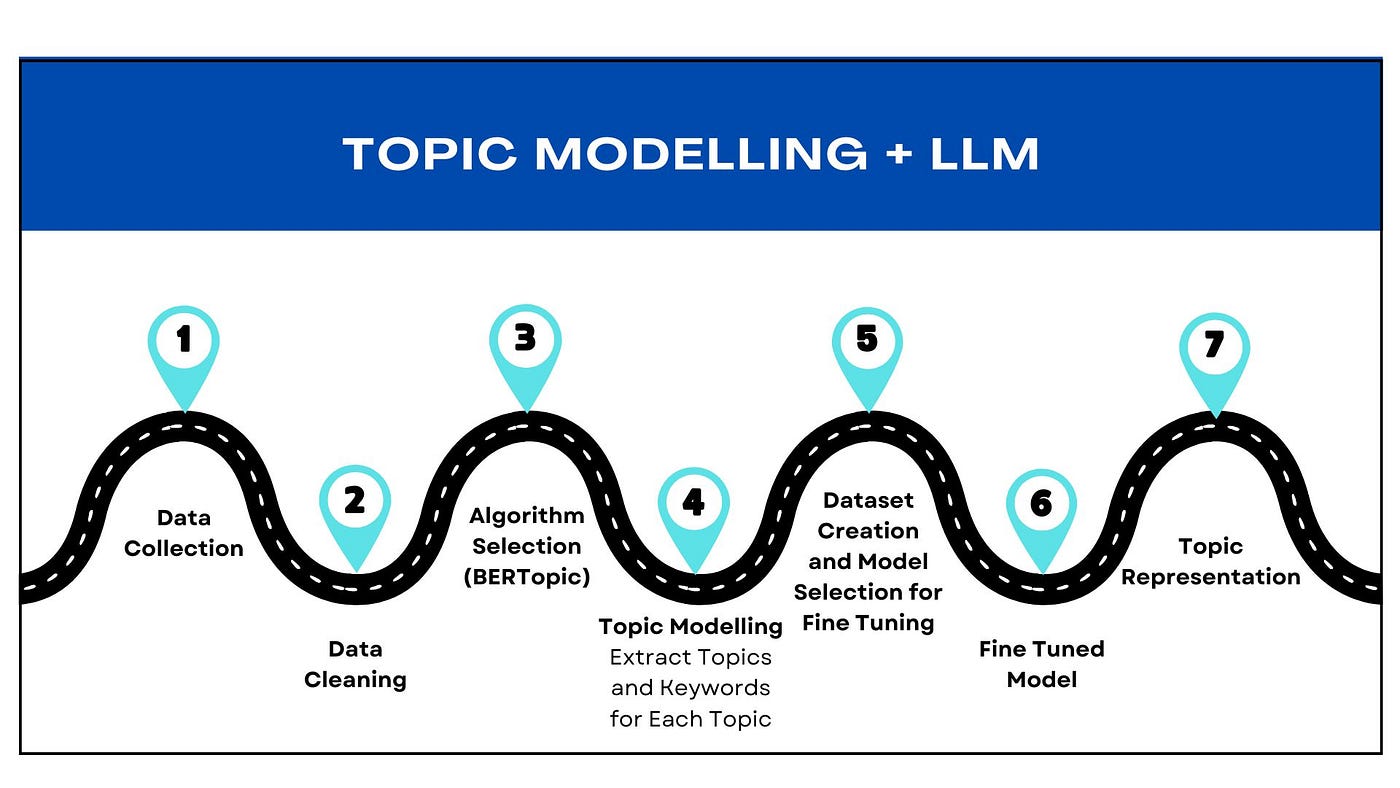
Topic modeling, a statistical technique in natural language processing (NLP), aims to identify abstract topics in a document collection. It automatically extracts patterns from unstructured text, aiding researchers in understanding underlying themes. In each document, there are different topics, and each topic has its own set of words. The goal is to discover these hidden topics by studying how words appear together.
BERTopic, a topic modeling technique, harnesses transformers and c-TF-IDF to form dense clusters, ensuring easily interpretable topics with key words. This results in meaningful document clusters, particularly adept at handling large datasets. By leveraging BERT embeddings for semantic insight, BERTopic offers a robust approach to topic modeling. Developed in 2020 , BERTopic revolutionizes text analysis by extracting rich, interpretable topics from diverse datasets.
Here’s how BERTopic works:
- Document Embeddings: BERT generates dense vector representations (embeddings) for each document, capturing their semantic meaning.
- Dimensionality Reduction: High-dimensional document embeddings are then reduced using methods like UMAP or t-SNE, aiding visualization and clustering.
- Clustering: Traditional algorithms such as HDBSCAN group similar documents based on their embeddings.
- Topic Representation: Clusters yield representative keywords using TF-IDF or statistical methods, revealing prevalent themes.
- Interpretation: Clusters and keywords are interpreted to grasp underlying topics.
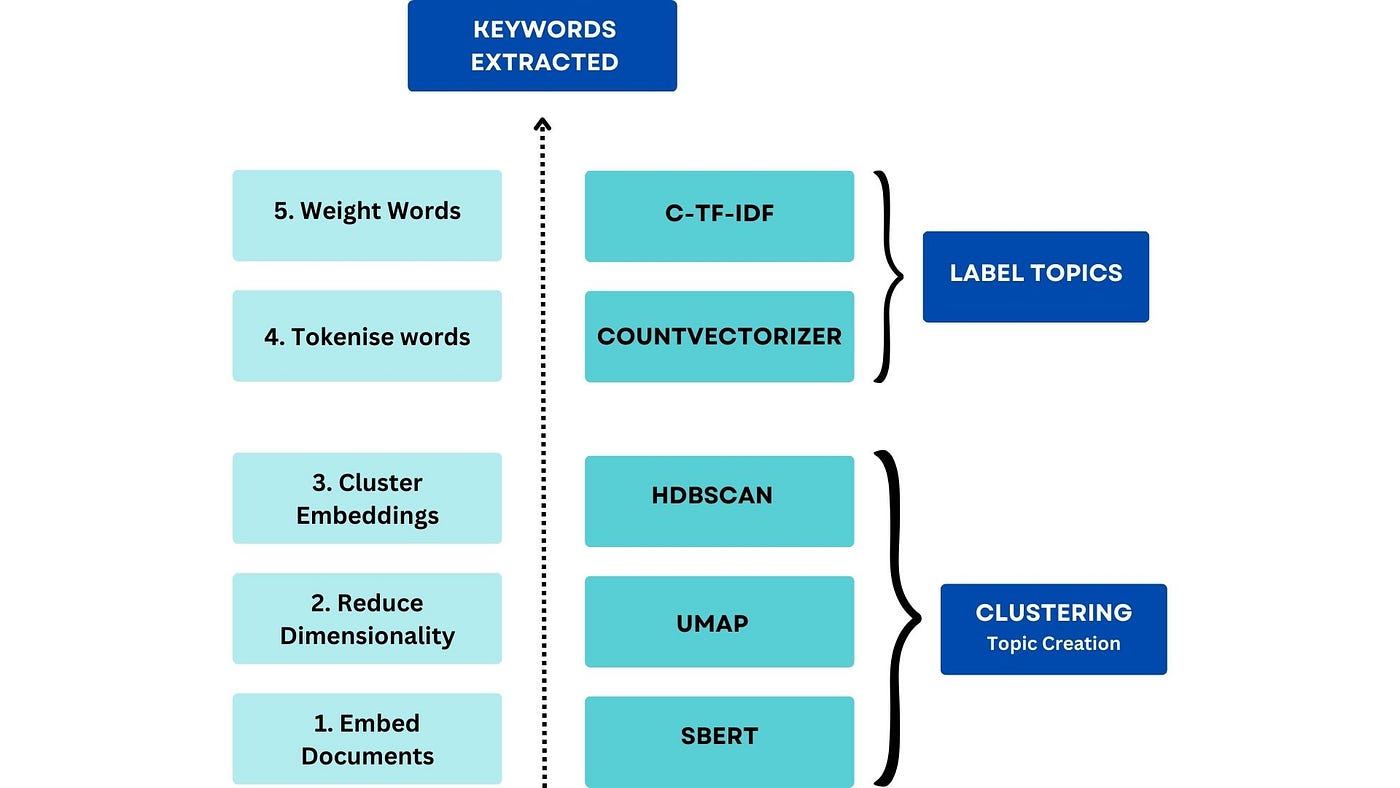

Utilizing BERTopic, the algorithm identifies 3 main topics and extracts 10 keywords for each. Additionally, the image indicates the distribution of articles among these topics, revealing the number of articles associated with each topic among the total input articles.
Transitioning to Language Models
For topic modeling, BERTopic extracted meaningful document clusters from the dataset. Next, attention shifted to topic representation, where Language Model-based methods (LLMs) were utilized. LLMs, like GPT 3.5 , Llama2 and T5, are specialized machine learning models trained on extensive text data. They excel in understanding and generating human language, performing various natural language processing tasks with their rich language representations.
Understanding Zero-Shot Prompting
Zero-shot prompting represents a groundbreaking advancement in natural language processing, where language models generate responses solely based on prompts, devoid of task-specific training. This approach empowers models like GPT-3.5 and LLAMA2 to understand and handle various questions, even if they haven’t encountered the task before.
GPT-3.5 vs LLAMA2: Established Powerhouse vs Promising Newcomer
GPT-3.5, an established powerhouse in this domain, excels in zero-shot prompting due to its extensive training. Its proficiency stems from exposure to diverse language patterns during training, enabling it to provide accurate and insightful responses. GPT-3.5’s versatility and reliability make it a preferred choice for prompt-based tasks, ensuring contextually relevant outputs.
On the other hand, LLAMA2, a promising newcomer, exhibits potential in understanding the essence of prompts and generating relevant responses. However, it may require fine-tuning for optimal task integration, and its initial outputs may differ from GPT-3.5. Despite challenges, LLAMA2’s ability in understanding detailed prompts suggests a bright future ahead. Refinement and fine-tuning are expected to enhance LLAMA2’s performance, unlocking new possibilities in natural language understanding and generation.
Building a Bridge: Creating a Dataset for Fine-Tuning
Fine-tuning involves adjusting the internal parameters of a Language Model (LM) to enhance its performance on a particular task. In our case, we aimed to refine GPT-3.5’s ability to generate clear and concise one line summary using provided keywords. Diversity was prioritized, necessitating a dataset covering various sectors and topics. This ensured the LLM’s proficiency across a broad spectrum of content.
Prompt-based fine-tuning is a specialized technique where the LLM is trained to generate text based on given prompts or instructions. Instead of starting from scratch, this method adjusts the model’s parameters to improve its understanding and text generation capabilities in response to prompts.
The emergence of small language models (SLMs), demonstrated by Phi2, signifies a pivotal advancement in natural language processing. Phi2 achieves competitive performance across NLP tasks like text classification and sentiment analysis while requiring fewer computational resources. Its significance lies in enabling broader accessibility and deployment in real-world applications.
Below are the steps to Fine-tune a Model:
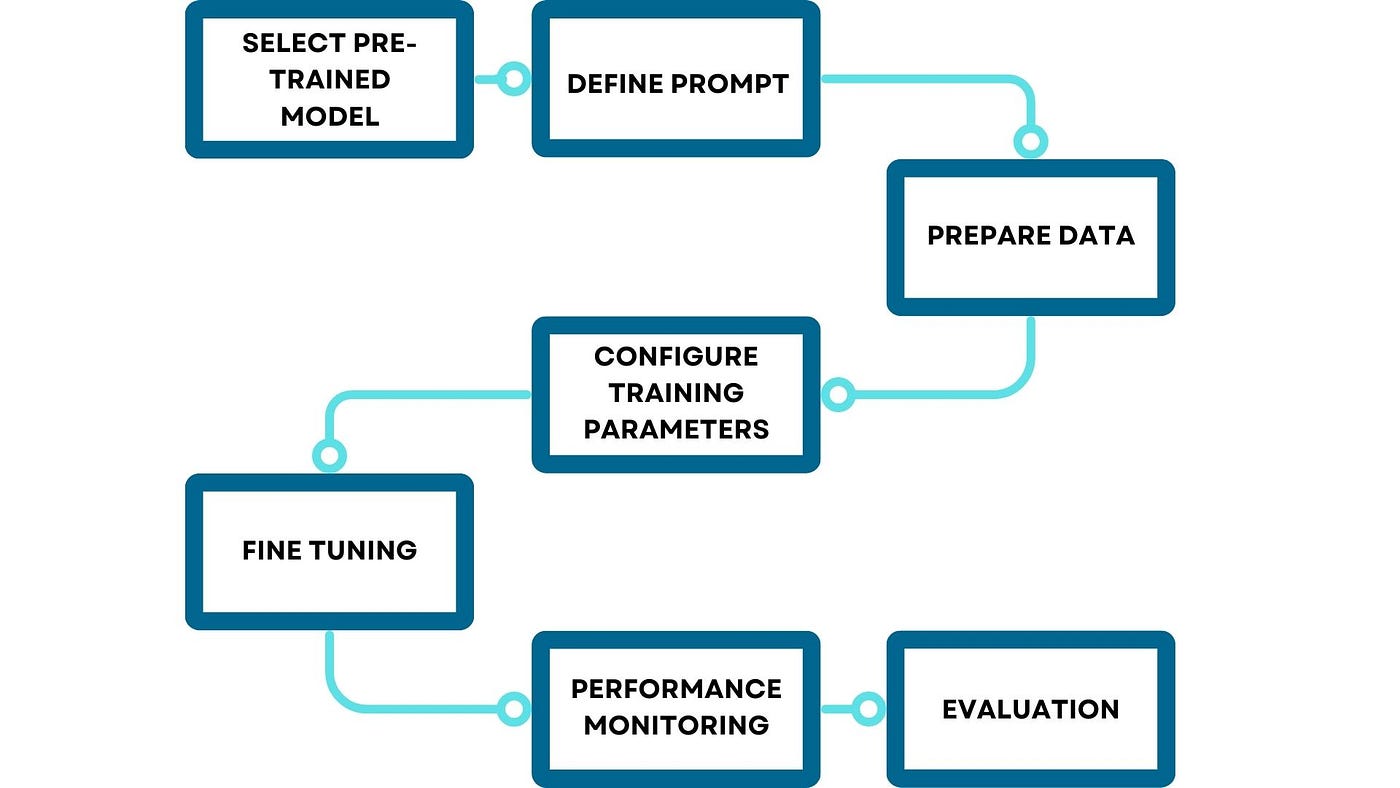
The fine-tuned models of LLAMA2 and Phi2 have yielded positive results. However, an issue arises with the output generation. In the case of Phi2, the output doesn’t adhere to the expected format, requiring additional post-processing steps, posing challenges for integration into applications. Another challenge involved the limitations of some SLMs in handling complex instructions. For example, Phi2, despite showing promise after fine-tuning, struggled with prompts that contained a high degree of nuance or required post processing beyond simple keyword association. These challenges highlight the need for continued research and development to enhance the adaptability and robustness of small language models for diverse applications.
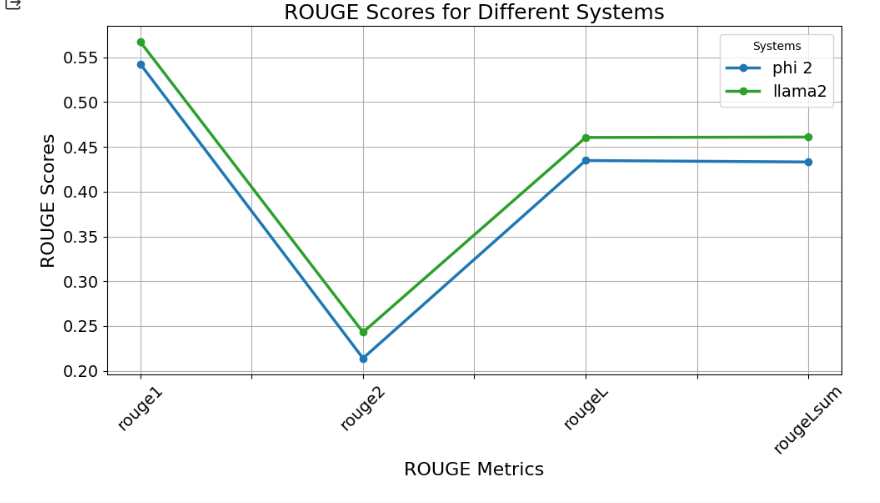
Below is an image displaying the Rogue evaluation results for fine-tuned Phi2 and Llama2. While both models show similar overall performance, Llama2 exhibits slightly better accuracy compared to Phi2. This might be because of the challenges faced by SLMs mentioned earlier, such as fine-tuning challenges and inconsistencies in output formatting. Improving SLMs could help overcome these issues and lead to better results in evaluations .
The above image depicts the results obtained from running a fine-tuned model. This model utilizes a list of keywords extracted from BERTopic as input to generate topic representations from Fine-tuned Llama2. These representations are concise one-line summaries highlighting the main topics covered in the documents.
Conclusion
The convergence of topic modeling algorithms and Large Language Models (LLMs) offers a strong way to study text automatically, which can change many areas. In market studies, companies can see what customers think and spot new trends from social media and online reviews. Financial experts can use this to find important themes in financial reports, helping with smart investment choices. In healthcare, researchers can uncover insights from medical literature to enhance patient care and treatment strategies. As AI gets better, we can expect more advanced tools for reading text, making it easier to find hidden stories. Using BERTopic and LLMs together can dig deeper into big collections of text, making new ways to understand information.
To see the practical implementation of the same visit-
AlgoFabric: https://algofabric.algoanalytics.com/
