By Kevin Stephen, Intern at AlgoAnalytics
In 1998, Yann LeCun and Yoshua Bengio introduced what is now one of the most popular models in Deep Learning, “Convolutional Neural Networks”[1](CNNs). A simple grid-like topology can help solve time-series problems using a 1D convolution or can work on image data treating it as a 2D grid. Fast forward to 2017, and here stands Geoffrey Hinton with his own improved version of Convolutional Networks, “Capsule Networks”[2]. A simple question arises, “Why replace something that already works so well?”. Well, maybe CNNs don’t really work as well as they could. Here are a few reasons why:
Reason 1: The basic working of Convolutional Neural Networks is that each convolutional layer extracts features sequentially. The initial layers extract the most blatant features and as the model progresses it learns to extract more features. As a result, convolutional layers do not encode spatial relations.
Let me illustrate this with an example shown in Figure 1.
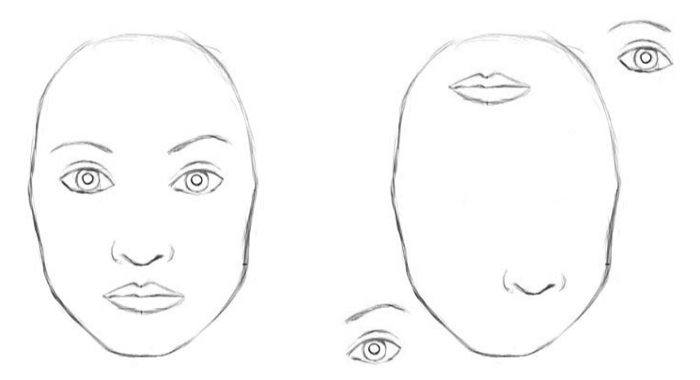
Figure 1: CNNs would classify both as faces due to lack of spatial information
Convolutional Networks would recognise both the images as faces.
CNNs do not encode pose and angular information.

Fig 2. Yet another example of CNNs misclassifying a face
As a result, CNNs would categorise this as a face as well. CNNs are also incapable of recognising orientation and Max Pooling does not provide “ViewPoint Invariance”.
Example: SmallNORB images (Figure 3.) from different viewpoints. The dataset contains images of the objects captured from different angles, and the objective is to identify the object with a model trained on the same images viewed from another viewpoint. Capsule Networks trained to detect objects in this database increased the accuracy by 45% over traditional CNN models. The dataset involves the same object shot from different viewpoints. Because the Capsule Networks has the added advantage of “ViewPoint Invariance”, it tends to classify these images of the same object in different orientations better.

Fig 3. SmallNORB images(Same object with different orientations call for Capsules)
Reason 2: Highly inefficient Pooling layers
In the process of Max Pooling (Figure 4), lot of important information is lost because only the most active neurons are chosen to be moved to the next layer. This operation is the reason that valuable spatial information gets lost between the layers. To solve this issue, Hinton proposed that we use a process called “routing-by-agreement”. This means that lower level features (fingers, eyes, mouth) will only get sent to a higher level layer that matches its contents. If the features it contains resemble that of an eye or a mouth, it will get to a “face” or if it contains fingers and a palm, it will get sent to a “hand”. This complete solution that encodes spatial info into features while also using dynamic routing (routing by agreement) was presented by Geoffrey Hinton, at NIPS 2017; Capsule Networks.
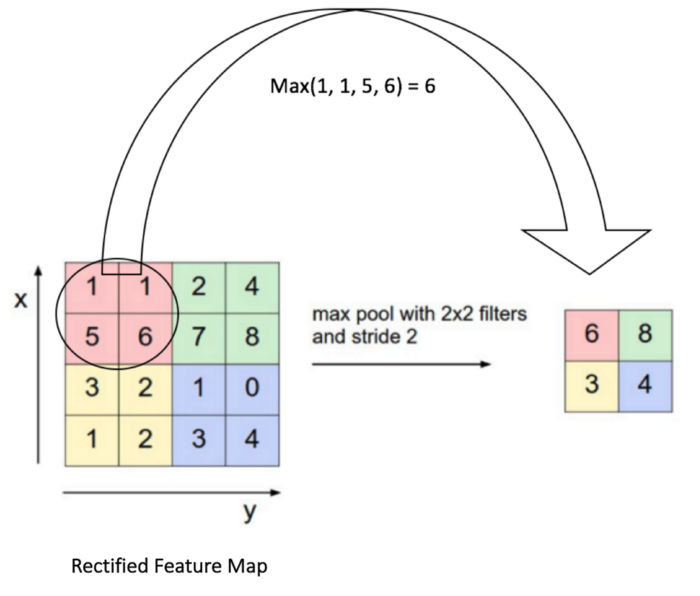
Fig 4. Max Pooling layer
What are capsules?
Capsule Networks are a new class of networks that rely more on modelling the hierarchical relationships in understanding an image to mimic the way a human brain learns. This is completely different from the approach adopted by traditional neural networks.
A traditional neuron in a neural net performs the following scalar operations:
- Weighting of inputs
- Sum of weighted inputs
- Nonlinearity (Activation)
Capsules have the following steps:
- Matrix multiplication of input vectors with weight matrices. This encodes important spatial relationships between low-level features and high-level features within the image.
- Weighting input vectors. These weights decide which higher level capsule the current capsule will send its output to. This is done through a process of dynamic routing.
- Sum of weighted input vectors.
- Nonlinearity using “squash” function. This function takes a vector and “squashes” it to have a maximum length of 1, and a minimum length of 0 while retaining its direction.
Dynamic Routing:
In this process of routing, lower level capsules send its input to higher level capsules that “agree” with its input. For each higher capsule that can be routed to, the lower capsule computes a prediction vector by multiplying its own output by a weight matrix. If the prediction vector has a large scalar product with the output of a possible higher capsule, there is top-down feedback which has the effect of increasing the coupling coefficient for that high-level capsules and decreasing it for others.

Fig 5. Dynamic Routing Algorithm [2]
This brings us to using Capsules in the real world.
Do capsules effectively replace convolutional layers in other models such as Segmentation and Object detection?
Let’s look at segmentation using Capsules.
We especially focus on the SegCaps model based on a UNet and an application in the ophthalmology field.
We can change the convolutional layers with capsule layers and create a new architecture. The main advantage here is that we can encode spatial relations for Semantic segmentation. The architecture is given below(Fig 6.).
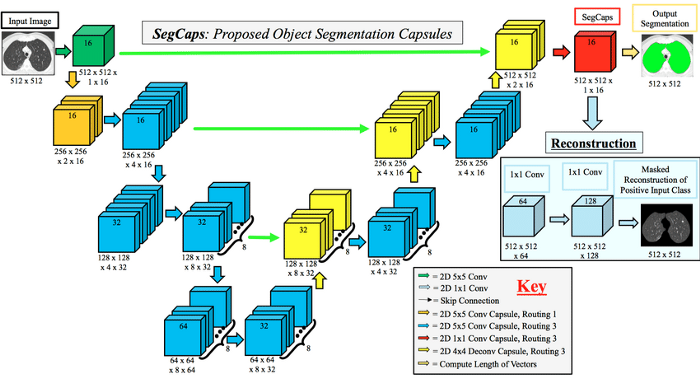
Fig 6. SegCaps architecture[4]
An advantage is the removal of heavy backbones. We achieve a large decrease in the number of trainable parameters. A regular U-Net has 31.1 M parameters but the SegCaps has only 1.3M parameters. However dynamic routing requires iterative updation and thus we do have some increase in complexity.
We test this model out on the OCTAGON dataset[3] for OCT-A scans to segment and generate the Foveal Avascular Zone or FAZ area[5].
Results

Fig 7. Results comparison
While the images seem very similar, in our observation Capsule Networks seem to be more sensitive to irregularities as compared to a normal U-Net while having a considerably lighter model and completely removing the need for a heavy backbone.
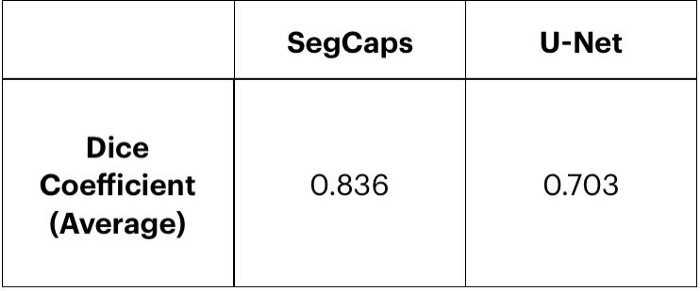
We compared our model performance with a U-Net over a test set of 14 images and the results are as shown in Table 1. We use a common metric used to evaluate segmentation models called Dice Coefficient (Dice Coefficient is 2 X the Area of Overlap divided by the total number of pixels in both images). As seen in Table 1, The Dice Coefficient for Capsule Networks is 0.84 compared to that of 0.7 for CNNs, indicating better results with Capsule Networks.
Summary
Although Convolutional Neural Networks(CNNs) work satisfactorily, there are a few limitations in the architecture. Capsule Networks aim to solve these by providing a novel approach. Capsules and their ability to encode spatial relations could be the next big thing in Computer Vision as it seems to be of great purpose in pose related models.
Further, with ever growing model sizes and an ever rising number of trainable parameters, it is necessary to limit the increase and focus more on practicality and adhering to the current hardware limits. Capsule Networks are a step in the right direction towards building truly intelligent Deep Learning models.
For demo visit our link https://algoanalytics.com/demoapp
For further information, please contact: info@algoanalytics.com
References
- Object Recognition with Gradient Based Learning by Yann LeCun http://yann.lecun.com/exdb/publis/pdf/lecun-99.pdf
- Dynamic Routing between Capsules by Geoffrey Hinton https://papers.nips.cc/paper/6975-dynamic-routing-between-capsules.pdf
- Octagon Dataset by VARPA group http://www.varpa.es/research/ophtalmology.html
- Capsules for Object Segmentation by Rodney LaLonde https://arxiv.org/abs/1804.04241
- Foveal Avascular Zone by Bryan Willian Jones https://webvision.med.utah.edu/2011/08/foveal-avascular-zone/
Code available at: https://github.com/kevins99/SegCaps-Keras
